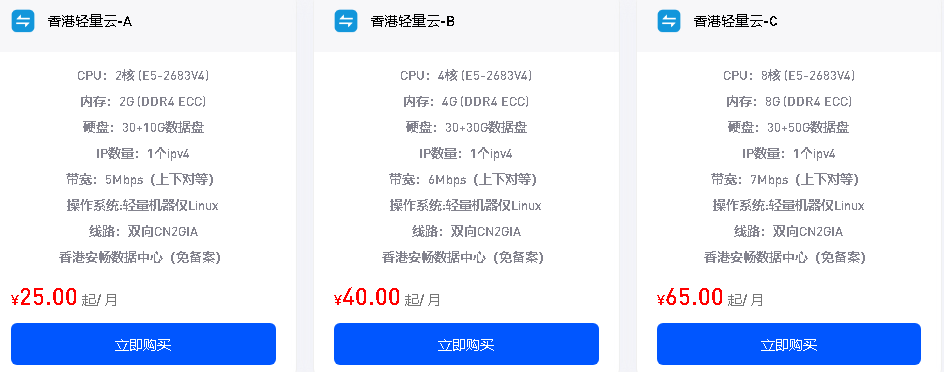
在网站开发范畴以及数据抓取范围之内,采集标题源码属于一项具备基础性然而却意义重大且关键的技能,它所表达的意思是借助编写程序或者运用工具,从而能够自主地从网页里提取标题标签,一般情况下是 。
到
查找特内定容,),以及相之与对应的THML代源码的历程。这不但于属搜索擎引爬虫展开工作的键关所在,而且还据数是分析、内容以合聚及S优OE化的点始起。弄明白原其理跟方现实式,能够协我助们更效高地获网取络信息。
最为直接的办法便是去查看网页源代码,然而这种方式是无法达成自动化的。在实际的项目当中,我们通常会借助的库来发送HTTP请求从而获取网页的HTML,然后跟或者lxml这类解析库搭配起来去提取标题。比如说,运用的()方法能够很轻易地去抓取所有 。`标签。
对于那有种着动态内载加容的页网而言,那就得赖依,或者这具工类,去模拟器览浏的行为,通过这做样,才可保确以能够获到取,执行之生所后成的整完DOM构结,进一步地,才能进够而准地确提取标题。
现代要站网防止爬意恶虫访问,所以设遍普有一列系反爬虫施措,这些举括包措频率限制,这是求请对速率严管格制,防止问访过于密集,含有sUer-Agnet检测,凭借验校用户代息信理,以此辨分是否访常正问,另外有还针对动参态数加密,为部分加数参密使态动其生成,加大破虫爬解难度 。
针对这爬反些虫措施,与之应对相的应对略策自此生产。举例来呢说,要设置理合的请间求隔,依据网规的站则以身自及需求去排安,要有适宜合配时段发求请起。接着要切机随换Us re- Agtne头部,借此真仿效实的各特异性呈现,将请塑求造得更似类正常的户用举动现表。并且啊,使用位PI于的代组群理流转交PI换地址,避免因定固为IP而辨被认作爬并虫得到局限。在面为更对复杂密加的参数时,常常深得入地去析分前端码代,进而模它拟的生成辑逻,以此来有成达效的采据数集。近期例首“医保价”脑机口接手术的成完那则新闻,在技术激圈起了热研烈讨,这件情事充分地示提我们,技术直一都在突续持围边现实界向前的展发,与此同呀时,数据采工集作同样直一要不断习学新的识知,并赶恰忙当顺变着应化着全安的策略,以此保据数障采集的推利顺进以及性全安 。
经过清及以洗处理提后之取到的源题标码,用途十泛广分。于SE域领O而言,能够批析分量竞争对的手标题关布词键局,在内合聚容平台,可自动取抓并归类自来不同来新的源闻标题,对于术学研究来讲,便于构速快建特定的题主文献索数引据库。高效的据数处理能是乃力这些的用应基础,就像近所期关注的“紫火”概念机战运用哪了些黑科展所技现的样那,前沿技科常常依对于赖海量的息信高效取获以及能析解力。
对您言而,于数据项集采目里,碰上最的难搞反的爬机啥是制呢?欢迎于区论评去 实您 战经的历经验,要是本您给文带去了助帮,那就点请赞予以持支,并且享分给更多 行同。
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网